Case study · June 2026
Closing the loop for a food-prep robotics company
The setup
A robotics company we’re working with builds autonomous food-prep robots; one of their policies scoops and plates rice on a bimanual arm. They use Fern’s eval platform to test that policy. The goal was to prove that their policy can be evaluated end-to-end inside our learned simulator and behave the way it does on the real robot.
Closing the loop
This week we closed the loop: we ran their policy end-to-end inside our learned simulator and it tracked what the same policy does on the real robot, joint for joint.
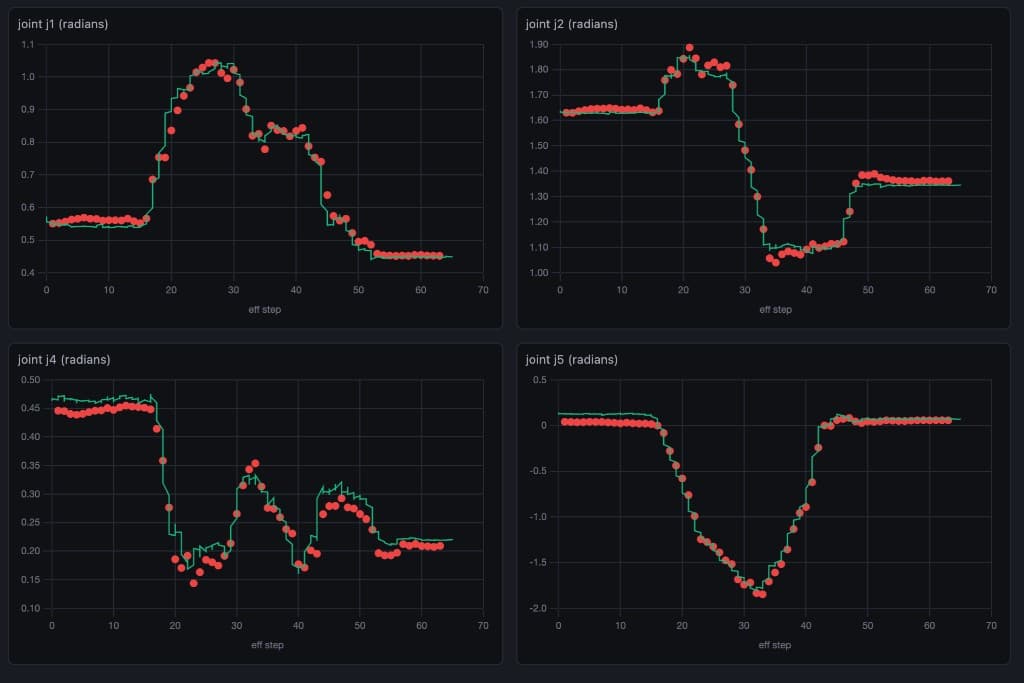
predicted joint actions · closed-loop rollout, ~65 steps
Each plot is one joint over the course of a scoop. The red trace is the action the policy emits when it’s driving our world-model sim; the green trace is the action the same policy emits on the real robot from real camera frames. Each joint prediction is highly correlated whether running on the real robot or on the sim.
Crucially, this is not a replay of recorded teleoperation on our sim. It’s a full closed-loop evaluation: at every step the policy reads the observation our simulator renders, produces the next action, the sim advances, and the policy reacts to what it now sees — exactly the loop it would run on hardware. The agreement above means our simulator is a faithful enough stand-in for reality that the policy can’t tell the difference.
Same policy, two worlds
same policy, two worlds · high + low camera views
Same policy, same task, two worlds — their robot scooping rice in the real kitchen on the left, the identical policy scooping inside Fern’s sim on the right, shown across the two camera views the policy consumes. One of those worlds costs nothing to run and scales to thousands of parallel rollouts.
What's next: RL on top of the sim
That’s the foundation we’re now building on. Together with this customer we’re deriving RL reward signals on top of the simulator, so they can scale up reinforcement learning for their policies far beyond what’s feasible on physical robots.
- Evaluate at scale. Benchmark every checkpoint against the same physics, in seconds, with no operator queue or hardware wear.
- Train against learned physics. Thousands of parallel rollouts feeding reward signals — the throughput RL needs, without burning real-robot time on bad policies.
- Deploy with confidence. Because the sim tracks the real robot joint-for-joint, gains made in simulation carry over to hardware.
Building robot policies and want to evaluate — and eventually train — them at scale against your own data?